
What’s High Availability
High availability is a critical success factor for any given enterprise application. Today we’ll go through how to design and deploy an application with high availability. First things first. Let’s see what’s high availability.
High availability is a characteristic of a system, which describes the duration (length of time) for which the system is operational. – Wikipedia
In simple words high availability can be defined as running a system 24*7 without a downtime even if there are hardware and software failures. In other way a fault tolerance application. This helps ensure uninterrupted use of the application for it’s intended users. If you need more information you can read this article. Also you might be thinking when is the right time to introduce high availability in your application? The answer is here.
Following is an architecture that supports high availability. It’s the minimal requirement to implement high availability in your application(Note that in the database cluster you can have master-slave instead of master-master depending on your requirement).
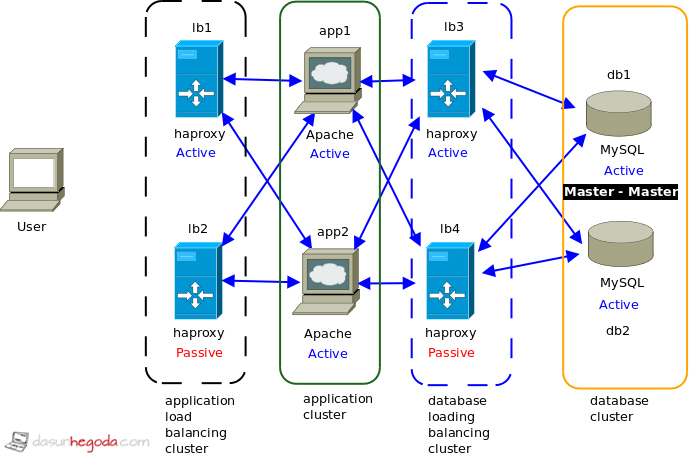
Without beating around the bush let me elaborate this more.
- lb1 & lb2 are load balancers for the application servers. All together we call them application load balancing cluster.
- app1 & app2 are application servers. All together we call them application cluster.
- lb3 & lb4 are load balancers for the database servers. All together we call them database load balancing cluster.
- Then we have the database cluster at the end that are db1 and db2. All together we call them database cluster.
- Active means particular component is accepting requests and passive means particular component is not accepting requests but when the active component is down passive component will take over and will start accepting requests.
Let’s take an example and discuss this future more.
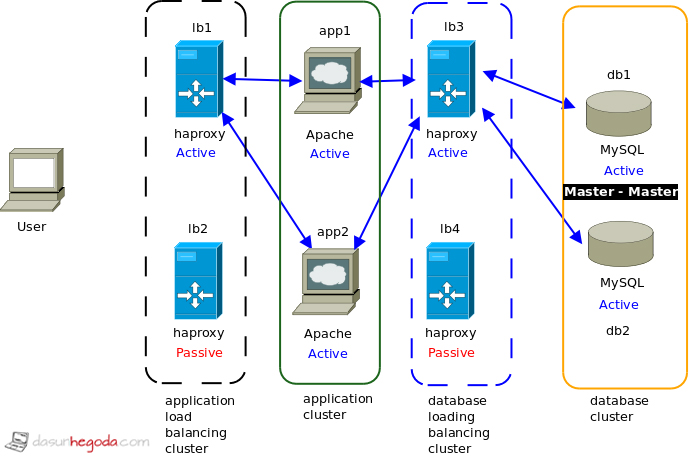
On a happy day user will make a request. The request will be accepted by lb1 and depending on the load balancing algorithm in lb1 request will be passed to the app1 or app2. From there the request will be handed over to the lb3 by app1 or app2. lb3 will communicate with the database. The response will follow the same path as the request’s path. Okay now let’s get ready for some action because you can’t expect a happy day everyday.
What if the lb1 is down
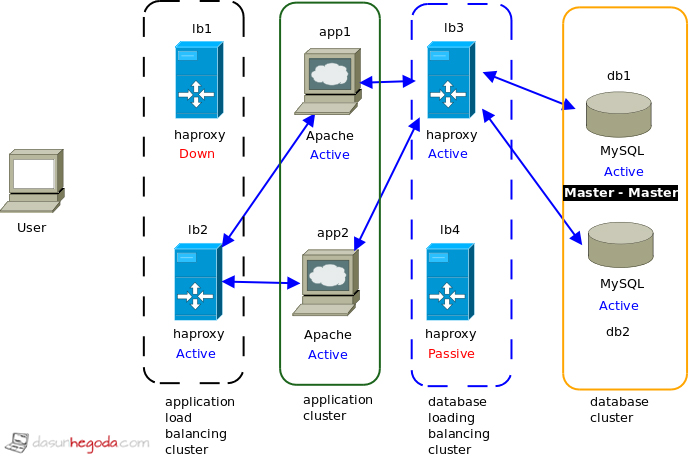
Here even though lb1 is down lb2 has taken over and now lb2 is in active status. System is functional even though one load balancer has failed. Best part is here users will not experience any downtime of the system due to the failure of lb1.
Let’s assume app1 is down
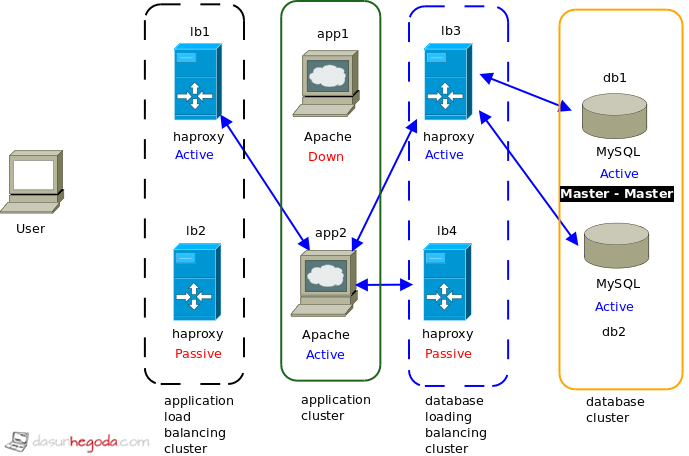
(For the time being please ignore arrow from app2 to lb4. I’ll correct it ASAP)
Now you can see even though one application sever went unavailable system is functional without an issue. Just like the previous example.
Now let’s take the worst case scenario where 4 components are down
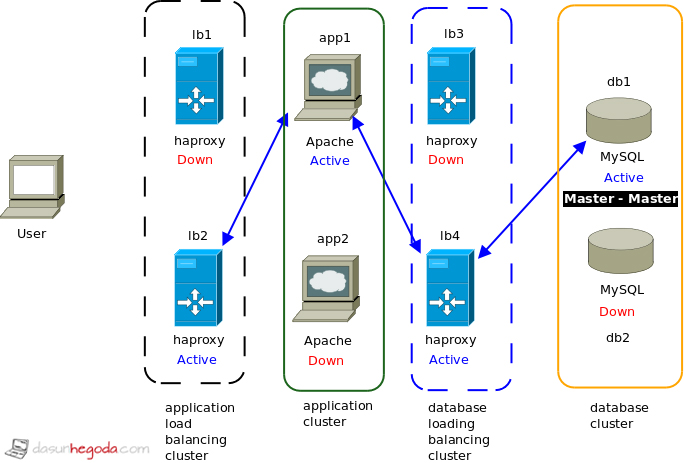
Oh! Nooohhhh!!! Here a single component is unavailable from each cluster that means four components are not unavailable altogether. Will the application be able to function as on a happy day? Yes, a big yes. You can image the power of having high availability in your application. Even though a single component or multiple components are unavailable your application will be available for it’s intended parties without an issue. Perfect right!!!.
Okay now you might be wondering how this architecture can be implemented. What are the steps to get this done. Don’t worry I got you. I have already written articles that guide you to implement this architecture very easily. It’s just a matter of combing them all together.
- Setting up application load balancing cluster – How to setup HAProxy with Keepalived & Apache Load Balacing with HAProxy
- Setting up database load balancing cluster – How to setup HAProxy with Keepalived & MySQL Load Balancing With HAProxy
- Setting up database cluster – MySQL Master-Master Replication
So that’s it about high availability deployment architecture. If you have any questions let me know in the comments below. Your feedback is highly appreciated(happy-face).
![]()

The Architecture looks Good but not complete, as user will call which HA proxy ?
Pingback: failover - Conmutación por error de & Recuperación de Desastres
Thanks for the article, really nice and easy explanation of HA